
Recommendation Systems

I am a Technical Writer and an Open Source Fanatic.
In the past weeks, I had an opportunity to explore different concepts in Deep Learning and stumbled upon a very interesting topic about Recommender Systems and how machine learning plays a pivotal role in creating them. In this article, we are going to delve into the basics of recommender systems.
What are Recommendation Systems?
A recommender system is a subset/class of information filtering system that anticipates the evaluation or preference that a user would feed to an item, in simple terms recommender systems are software tools used to provide suggestions to a user according to their requirements.
Types of Recommendation Systems
Recommendation systems use different techniques but we are going to mainly focus on the two most popular used filtering systems.

Collaborative Filtering
Collaborative filtering (CF) is the most commonly used technique in designing recommender systems. Most popular websites like Netflix, IMDb, and Amazon make use of collaborative filtering. In this technique, collaborative filtering establishes its method by gathering data and examining information based on a user to make predictions by looking at similarities with other users.
Different types of Collaborative Filtering :
Memory Based Filtering - this technique makes use of user rating information to anticipate the similarities between the users and items to make predictions/recommendations.
Model-Based Filtering - in this technique we create a model by extracting information from the rating dataset (using data mining) and use the model to make recommendations/predictions.
Content-Based Filtering
Content-based filtering(CBF) algorithms recommend items to a user based on similarity count. The best matching items are recommended by comparing various items which a user previously rated before. For example, if I go to an online store and like a particular android phone, the content-based filtering algorithms will recommend pages related to android devices.
Getting Started
Now that we have laid the foundation of understanding recommender systems, let’s delve into the things needed to get started in building a recommendation system collaborative filtering model.
Data
Data is the most important must-have tool when it comes to building applications in deep learning. In this particular case, we’ll need data that contains a set of items and users that have already rated or reacted to these items. The ratings can range from 1 to 5 showing the most liked or disliked product. When working with this type of data, it will mostly form a matrix whereby each row would contain ratings given by a user and each column would contain ratings received for each item.
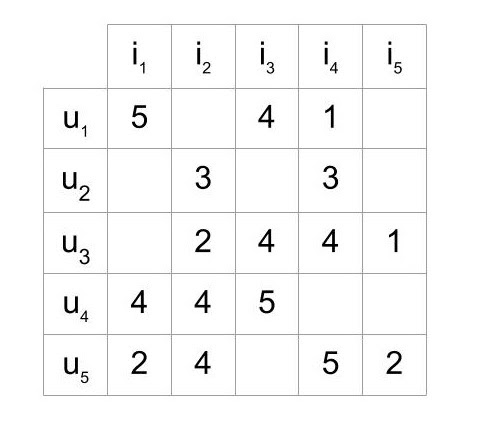 (ratings matrix)
(ratings matrix)
In the example shown above, we have five users who have rated five items. Some cells in the matrix don’t contain any information as it is unlikely for users to rate or react to every item they come across. These particular empty cells are called sparse and the mostly filled cells are called dense.
Steps Involved
To build a system that can automatically recommend items to users based on their preferences, the first step is to find similar items and users. The next step is to predict the item ratings that a particular user has not rated.
To get started, we need to solve the following problem statements :
- Determine which users or items are similar to one another.
- Discover the similarities between the users or items and establish the rating a user would give to an item based on the ratings similar to other users.
- Measure the accuracy of the ratings that were calculated.
Approach
- Because collaborative filtering contains different types of algorithms, there are multiple ways to find similarities between users and items or multiple ways to calculate ratings based on similar users. Depending on the preferred approach used, the end result would still be a collaborative filtering method.
- One crucial thing to bear in mind, in the collaborative filtering approach the similarities are not calculated by using factors such as the age of users or genre of movies but are strictly calculated on a rating basis (either implicit or explicit) a user gives to an item.
- When approaching to solve the measure of accuracy from your predictions, there are multiple techniques used like error calculation.
Error Calculating Techniques
One of the approaches used to measure the accuracy of your results is the Root Mean Squared Error(RMSE). In this technique, you predict ratings from a test dataset of user-item pairs whose ratings values are known(available). The difference between the known values and the predicted values would now be the error. We square all the error values from the test set, find the average(or mean) and take the square root of that average to get the RMSE. Another metric used to measure accuracy is the Mean Absolute Error(MAE). In this technique, we find the magnitude of error by finding its absolute value and taking the average of all error values.
Conclusion
Although there are several other recommender systems like demographic and hybrid filtering, it is very important to know that they all come with pros and cons. With that in mind, purpose and fulfillment are derived from the fact that the systems improve mankind's way of living by removing the burdens of principle time wastage. Users are in a better position to focus on other necessities as the recommender system enables them to do so with just one search click touch of a button.
Resources
1. https://developers.google.com/machine-learning/recommendation/content-based/basics
2. https://builtin.com/data-science/collaborative-filtering-recommender-system
3. https://towardsdatascience.com/essentials-of-recommendation-engines-content-based-and-collaborative-filtering-31521c964922
4. https://medium.com/analytics-vidhya/movie-recommender-system-using-content-based-and-collaborative-filtering-84a98b9bd98e




