
Getting Started With Deep Learning II
Part Two

I am a Technical Writer and an Open Source Fanatic.
Data comes in different forms either an image or text, but one thing is certain when it comes to deep learning, models don't understand words or sentences they only process tensors. In this section we are going to delve into how text data is encoded to tensors, exploring different methods to achieve this, and hopefully at the end we will have a basic understanding of how things work.
One hot encoding
One hot encoding is a method where data is encoded in form of vectors consisting of 0 beside 1 element. Each word encoded as a one-hot vector is unique meaning that each word in a sentence has a unique assigned vector. There aren't any instances where two words share the same vector. see image below

In the previous article we touched on why we need to use floating point numbers as the preferred data type for tensors. We are now going to see this in practice. The image above shows a representation of a one-dimensional tensor but in order for us to feed this information to the model, we need to convert the vectors to a tensor(floating point).
But why go through the trouble of converting data types instead of just feeding the vectors to the model?
When we take a look at the dimension of the vector, we see that all the 0 elements don't contain any information. This is a perfect example of memory wasted, remember each values has a storage property assigned to it. There isn't enough information to describe the dimension because the goal is that the more information the better. This is why we need to convert the vector to a tensor in order to save memory storage and be able to pass meaningful data to the model.
Embeddings
We have established a sense of how one hot encoding works however the technique is only effective when it comes to small datasets. How then do we apply it to large datasets without running out of memory while providing more dimensionality? To solve this issue, we can simply implement word embedding. Word embedding is a dense vector of tensors that represents words in a multidimensional space, where words that have a similar meaning have similar representations. Let's take for instance we have two sentences 'i love my dog' and 'i love my cat' , cat and dog will share a similar representation(encoding). see example below.

Let's explore at two mainly used algorithms use in Word Embeddings
Embedding Layer
Embedding layer is a word embedding that has been learned from a neural network model. It can be understood as a look-up table that maps one hot vector's indices to dense vectors(embeddings). The dimensionality of the embedding layer can be defined according to the task, and the weights are randomly initialized but gradually adjusted during training. Once trained, the learned word embeddings will roughly encode similarities between words.
Word2vec
Word2vec is a method that processes text to vectors of words. The word2vec is mainly based on the idea of representing words in their context. There are two major learning models that can be used as part of the word2vec in word embedding :
Continuous Bag Of Words - this model learns the embedding by predicting the current word, based on its context. The intuition behind this model is quite simple, given a sentence like 'I like my dog', we chose our target word to be 'like' and our context words will be 'i my dog'. What this model will do is take the distributed representations of the context words to try and predict the target word.
Continuous Skip Gram - this model learns by predicting the surrounding words given in a current word. It takes the current word as input and tries to accurately predict the words before and after this current word. This model essentially tries to learn and predict the context words around the specified input word, given a sentence 'let's go play outside', we can choose our input word to be 'go' and the model will try to predict ' let's play outside'.
Both models are focused on learning about words given in their usage context where the context is defined by the neighboring words. The main benefit of these algorithms is that they take huge amounts of words in a large dataset, and produce high-quality embeddings that can be learned efficiently while using low storage space, providing more dimensions, and taking less computation time.
Tokenizers
Tokenizers is a technique that splits text, breaking it down into smaller pieces called tokens. For example, 'The cat is sleeping' can be split into four tokens 'The' 'cat' 'is 'sleeping'.see example below.
Not only do tokens function in the splitting and breaking down of text, but they also give machines the ability to read text. This plays a pivotal role when it comes to model building and text pre-processing.
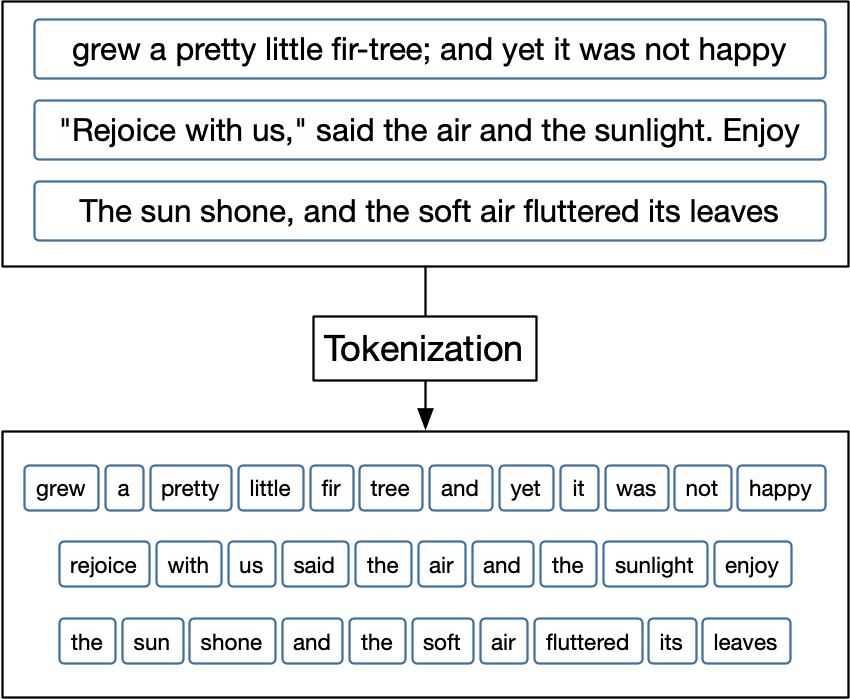 text representation of tokenization
text representation of tokenization
Let's look at the three most commonly used tokenization algorithms and see how they work.
Spacy
Spacy is a natural language processing library used in tokenizing text in tensors. The input to the tokenizer is text and the output is a sequence of objects stored in a DOC object. The DOC object is a container that holds an array of tensors and for this to be constructed, a vocabulary(vocab) that contains a sequence of word strings must be created. Vocab is a storage class used to store data during tokenization in order to save memory. During tokenization, spacy tokenizes text by applying specific language rules. For example, punctuation that is found at the end of a word is usually split but in the case of a word like 'N.Y.' it remains as a single token.
Subword
As the name entails, subword tokenizes text into subwords. For example, 'unfriendly' can be split as 'un-friend-ly'.One of the common methods subword uses is Byte Pair Encoding (BPE), which is popular when building transformer-based models. Subword uses character tokenization by taking one text data character at a time without grouping them. BPE helps subword by effectively tackling the concerns of running out of vocabulary words, and also strikes a good balance between performance and tokenization quality.
What is BPE
BPE is a data compression algorithm whereby the most frequent pair of bytes (word/token) of data is replaced by a byte that does not appear in the data. Let's take for instance we have data aaabdaaabac which needs to be encoded. The byte pair aa occurs frequently, so we replace it with Z as it does not have any occurrences in our data. So now we will have ZabdZabac where Z = aa. The next common byte pair is ab so we'll replace it with Y. We now have ZYdZYac where Z = aa and Y = ab. The only byte left is ac which occurs only once so we don't encode it. We can use recursive byte pair encoding to encode ZY as X. Our data has now transformed into XdXac where X = ZY, Y = ab, and Z = aa. There's no need to further compress the data as there are no more byte pairs appearing more than once. To decompress the data we start by performing replacements in reverse order. see example below
 source jaketae
source jaketae
We have seen how BPE works in general but when it comes to text tokenization, things work differently as we don't need any compressing. BPE ensures that the most frequent words are represented in the vocabulary as single tokens while less frequent words are broken down into two or more tokens. Suppose we have a preprocessed words 'low', 'lower', 'high', 'higher' , these words are spilt into characters. The bpe algorithm will look for the most frequent byte pairing, merge them and perform the same iteration until the iteration has reached the limit. That is why when it comes to machine translation, bpe is the most recommended tokenizer to do the job.
Sentence Piece
Sentence piece is a subword-independent text tokenizer and detokenize designed for neural-based text processing, where the size of the vocabulary is predefined before feeding to the neural model. lt implements subword segmentation algorithm's as a parameter for the trainer. In its mission to achieve the process, sentence piece uses main components which are a normalizer, trainer, encoder, and decoder.
Normalizer is when the logical-equivalent characters of information/text/data is converted into simpler forms. From the normalized corpus, the subword segmentation model is then trained (Trainer). Encoder internally executes Normalizer to convert input tokenizers into a subword sequence with the subword model trained by Trainer. The Decoder corresponds to postprocessing respectively where the subword is converted into normalized text. Similar to how it works with BPE, sentence piece achieves higher quality tokenization and reduces error when working with longer strings and characters. It also trains non-space languages like Chinese or Japanese with the same ease as with English and French.
Conclusion
Now that we have seen how text data can be converted to tensors and also established an understanding of how different tokenizers work, in the last section of the article we'll finally have a look at how models learn and see how different parameters influence the model's performance.
If you missed the first part of this article, you can find it here.




